

String input is a weird thing when it comes to wide characters, mostly because how the heck do you type wide characters in a terminal window beyond copy-and-paste?
For single character input, the wchar.h header defines three functions: fgetwc(), getwc(), and getwchar().
The fgetwc() and getwc() functions both read one wint_t character (wide-character int type) from a named file stream. The getwchar() function (actually a macro) reads wide characters from standard input. This is the function I prefer.
The wint_t wide-character integer type is larger (wider) than the wchar_t “character” type. The primary reason is to accommodate the end-of-file character,
WEOF, which is defined outside the bounds of a wchar_t variable. You can use plain old wchar_t variables with the functions, but when you’re hunting for the end-of-file marker with fgetwc() or getwc(), use wint_t instead.
The following code uses the getwchar() function to read wide characters one-at-a-time from standard input. The getwstring() function reads up to count characters or stops at the newline ('\n'), storing the result in the wchar_t string input:
#include <locale.h>
#include <wchar.h>
void getwstring(wchar_t *ws,int count)
{
int x = 0;
wchar_t *a,wch;
a = ws;
while(x<count-1)
{
wch = getwchar();
if( wch=='\n')
break;
*a = wch;
a++;
x++;
}
*a = '\0';
}
int main()
{
wchar_t input[10];
setlocale(LC_CTYPE,"UTF-8");
wprintf(L"Type some fancy text: ");
getwstring(input,10);
wprintf(L"You typed: %ls!\n",input);
return(0);
}
The getwstring() function uses the getwchar() macro at Line 12 to read wide-characters from standard input. The characters are read until the newline is input or the buffer is full. Then the string is capped at Line 19.
For the sample run, I copied and pasted text from a web page:
Type some fancy text: 你好,世界
You typed: 你好,世界!On the Mac terminal, you can press Control+Command+Space to see the Emoji and Symbols palette, which you can use to pluck out one character at a time, as shown in Figure 1.
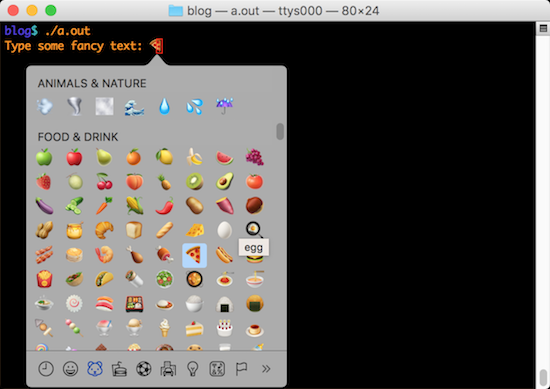
Figure 1. The weirdo character palette in the OS X Terminal program.
Instead of writing your own getwstring() function to read a wide-character string, you can use the fgetws() function. This function is the wide-character equivalent to my old pal fgets(). Here’s the updated code:
#include <locale.h>
#include <wchar.h>
int main()
{
wchar_t input[10];
setlocale(LC_CTYPE,"UTF-8");
wprintf(L"Type some fancy text: ");
fgetws(input,10,stdin);
wprintf(L"You typed: %ls!\n",input);
return(0);
}
As with fgets(), the arguments for fgetws() are a buffer, input size, and the file handle. For standard input, stdin is used, as shown in the code.
The code’s output is almost the same:
Type some fancy text: 你好,世界
You typed: 你好,世界
!The fgetws() function, like its fgets() twin, reads and retains the newline character. You can view my quickie solution for this effect here, if you want to eliminate the newline. I’ll present another solution in a future Lesson.
One more note: The terminal window assumes that every character displayed has the same width. Historically, terminals play with only ASCII text. In a GUI, the terminal assumes a monospaced font. A few Unicode characters, especially emojis, are wider than a single character position in the terminal window. The result is overlap, which you can kind of see in Figure 1.
The wcwidth() function returns the number of column positions for a wide character, though it’s not particularly useful. For example, the pizza slice shown in Figure 1 is more than 1 column wide, though the wcwidth() function returns a character width value of 1, which isn’t correct. My advice is to be cautious when showing such characters. If you plan on using a specific character, then you can eyeball the width and plan accordingly.