I’m a fan of the online game Spelling Bee. In this game, you use a combination of seven letters to spell various words. Each word is at least four-letters long and must contain a special letter, shown in the center of Figure 1. When you create a word that contains all seven letters, you’ve discovered a pangram.
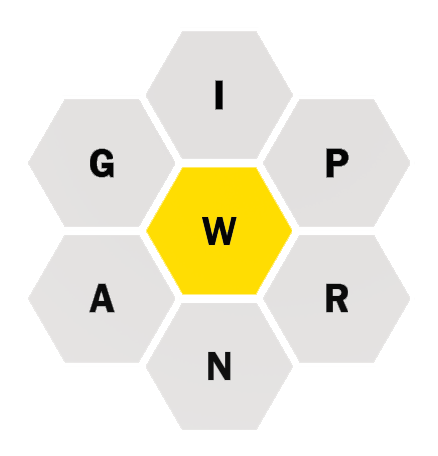
Figure 1. Seven tiles from the Spelling Bee game. One of the pangrams is WARPING, which uses all seven letters.
The Spelling Bee puzzle shown in Figure 1 has 34 correct answers. Each one contains at least four of the shown letters and all include the W, the center tile. It’s a fun game that inspires me to wonder how many words in English are pangrams?
According to the Spelling Bee rules, the answers cannot be proper nouns. They can occasionally be foreign words, though this rule seems inconsistent. Regardless, I’m inspired. I cobbled together code from last week’s Lesson to look for 7-letter words. Then I added an update to this month’s Exercise solution to look for unique characters in 7-letter words. Here is the result:
2023_11_18-Lesson.c
#include <stdio.h> #include <stdlib.h> #include <string.h> /* this code assumes the following path is valid */ #define DICTIONARY "/usr/share/dict/words" #define SIZE 32 #define LENGTH 7 #define TRUE 1 #define FALSE 0 int char_scan(char *a) { int size,x,y; /* obtain size */ size = strlen(a) + 1; /* scan the characters */ for( x=0; x<size-2; x++ ) { for( y=x+1; y<size-1; y++ ) { if( a[x] == a[y] ) { /* not unique */ return(FALSE); } } } return(TRUE); } int main() { FILE *dict; int unique; char word[SIZE],*r; /* open the dictionary */ dict = fopen(DICTIONARY,"r"); if( dict==NULL ) { fprintf(stderr,"Unable to open %s\n",DICTIONARY); exit(1); } /* scan for LENGTH-letter words */ unique = 0; while( !feof(dict) ) { memset(word,'\0',SIZE); /* clear buffer */ r = fgets(word,SIZE,dict); /* read a word */ if( r==NULL ) break; if( word[LENGTH-2]=='\'' ) /* skip possessives */ continue; if( word[LENGTH]=='\n' ) /* 7-letter word */ { if( char_scan(word) ) { printf("%s",word); unique++; } } } printf("I found %d pangrams!\n",unique); /* close */ fclose(dict); return(0); }
The char_scan() function is an update to digit_scan() from this month’s Exercise solution. The snprintf() function isn’t required as a string (a) is passed directly. I retained the size variable, though all strings should be 7-characters long. Otherwise, the function works the same as from this month’s Exercise solution.
The main() function scans for LENGTH size words, where LENGTH is 7 characters. For words of that size, the char_scan() function is called and, when TRUE, the pangram word is output and a tally kept.
When I ran the program without checking for pangrams, it reported 11,945 7-letter words in the dictionary file. After adding the char_scan() function, the output showed 4,078 pangrams.
The program isn’t perfect. For example, it flags the word vicuña as being 7-letters long. It’s probably interpreting the ñ as two-letters. Further, the Spelling Bee game tries to avoid plurals, where my program makes no such attempt.
All Spelling Bee puzzles have at least one pangram solution. Sometimes the pangrams can be quite long. For next week’s Lesson, I scan the digital dictionary to look for all possible pangram words seven letters or longer.
UTF-8 can use up to 4 bytes per character which could cause chaos with your program but should be reasonably straightforward to handle. I was reading something recently about sorting by Unicode characters but ignoring diacritics, so for example ñ would be treated as n. Unfortunately I can’t remember where I read it but there’s presumably a way to get a “base” letter from an ñ etc.
I expect the 3 and 4 byte characters are Egyptian hieroglyphics and stuff like that so unlikely to be in the dictionary!
btw I didn’t know what vicuña meant so had to Google it. Appears to be a cross between a sheep and a giraffe 🙂
I thought it was a camel!
Late to the party, but intrigued by all the possibilities for code enhancements the above discussion (with regards to vicuña) hints at—maybe, after the current series of blog entries on C23 niceties and features is finished, some articles on UTF-8 as well as Uɴɪᴄᴏᴅᴇ (+ some of its subtleties) could be of interest (before further development of these Spelling Bee programs):
• Clarifying the difference between bytes, code points, characters and glyphs?
(I.e. code-point = sequence of bytes, character = (possible) sequence of code-points [consisting of a base character followed by an arbitrary number of combining characters ↔ what the Uɴɪᴄᴏᴅᴇ standard calls a »grapheme cluster«], and glyphs being specific shapes representing these characters).
• How would one go about iterating over UTF-8 encoded Uɴɪᴄᴏᴅᴇ strings? (Thus being able to determine their length, i.e. strlen_utf8().)
• Whatʼs the concept of “Unicode equivalence” and how could NFKD (“Normalization Form Compatibility Decomposition”) help in handling diacritics?
Hereʼs a short Python session illustrating these concepts:
In [1]: import unicodedata
In [2]: name_bytes = b'H\xc3\xa0n The\xcc\x82\xcc\x81 Th\xc3\xa0nh'
In [3]: name_str = name_bytes.decode('utf-8'); name_str
Out[3]: 'Hàn Thế Thành' # The creator of “pdfTeX”
In [4]: len(name_bytes)
Out[4]: 19
# Decompose characters with diacritics to base characters
# that are optionally followed by “combining characters”:
In [5]: name_nfkd = unicodedata.normalize('NFKD', name_str)
In [6]: name_nfkd
Out[6]: 'Hàn Thế Thành'
In [7]: len(name_nfkd)
Out[7]: 17
In [8]: nfkd_utf8 = name_nfkd.encode('utf-8')
In [9]: nfkd_utf8
Out[9]: b'Ha\xcc\x80n The\xcc\x82\xcc\x81 Tha\xcc\x80nh'
In [10]: len(nfkd_utf8)
Out[10]: 21
If I had to do all (or any) of the above in “C”, I would probably rely on the “utf8proc” library (that is maintained by the development team of the Julia programming language), available under Linux through the "libutf8proc-dev" package and of which a Visual C++ compatible copy can be downloaded from my GitHub pages: http://tinyurl.com/yxdyp5f6
Should anyone need a short refresher on the above concepts, I recommend reading through Chapter 4 (“Unicode Text Versus Bytes”) of Luciano Ramalhoʼs excellent book »Fluent Python Clear, Concise, and Effective Programming«. A more technical discussion (besides the standard) can also be found under the heading "Strings and Characters" — http://tinyurl.com/3pz2jtdy — in Appleʼs documentation of the Swift Programming Language (arguably the first programming language to have done strings “the right way”).